コメント分析サービスのご案内
 お客様からの問い合わせや苦情の記録、アンケートのフリーアンサーなど、企業に蓄積されているデータのほぼ8割が非定型テキストデータだと言われています。
お客様からの問い合わせや苦情の記録、アンケートのフリーアンサーなど、企業に蓄積されているデータのほぼ8割が非定型テキストデータだと言われています。
これらのデータは、ただ蓄積しているだけでは価値を生むものではありません。少なくとも内容を読み込み、感覚にどのようなコメントが多いかを把握することが必要です。さらに「集計」や「分析」などの処理を行えば、読んでいるだけではわからなかった新たな価値を発見できることがあります。
 コメント分析サービスは、フリーアンサー等のコメント内容を各要素に分類、分析可能なデータに変換、グラフやクロス集計として表現し、大量の文書情報の全体像を容易に把握することを可能にするサービスです。
コメント分析サービスは、フリーアンサー等のコメント内容を各要素に分類、分析可能なデータに変換、グラフやクロス集計として表現し、大量の文書情報の全体像を容易に把握することを可能にするサービスです。
今まで、内容を読解するのに非常に多くの時間をかけていた。あるいは分析をあきらめていたフリーアンサーの内容を、グラフ化ならびにクロス集計によって簡潔に表現します。
“人の目”を通した分析サービスです。
 多くの日本人がアンケート等に書くコメントは、散文的で省略も多く、分析の場面で求められる「論理的で抜け漏れがない」文章とは対極にあるものです。
多くの日本人がアンケート等に書くコメントは、散文的で省略も多く、分析の場面で求められる「論理的で抜け漏れがない」文章とは対極にあるものです。
従来のソフトウエアに依存したテキストマイニングでは文章から「名詞」「動詞」「形容詞」を抜き取って処理する。あるいは単語の出現量統計を取る方法が一般的ですが、市販のツールには日本語の特質を捉えた文章解析機能が充分でないものが多く、分析結果も一般的なユーザが内容を理解するのは難しいものです。
また、特定品詞を抜き取る方法で文の質を揃えると、多くの重要な消費者の意見が無視されることがあります。また、新しい表現を発見することは不可能です。特にサンプルが少ない場合この傾向は顕著です。
 コメント分析サービスでは、フリーアンサー等のコメント内容を基本的に人の目で見て判断し、各要素に分類していくので、少ないサンプルでも高品質な分析が可能となります。
コメント分析サービスでは、フリーアンサー等のコメント内容を基本的に人の目で見て判断し、各要素に分類していくので、少ないサンプルでも高品質な分析が可能となります。
出力結果もシンプルにグラフやクロス集計として表現し、大量の文書情報の全体像を容易に把握することを可能にしています。
コメントの構造化
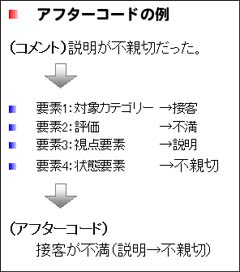
コメント分析サービスでは対象となるコメントを以下の4つの要素に分解します。分解された要素は数値化されたアフターコードにまとめられ各々のコメントに割り当てられます。
要素1:対象カテゴリー
まず、何について述べているコメントなのかを示す要素で、例えば、店舗評価についてのコメントを分析する場合は、(店舗環境/接客対応/品揃え/売場作り)などがそれにあたります。
要素2:評価要素
前述の対象カテゴリーに対して、どのような評価を下しているコメントなのかを示す要素です。一般的には(満足/不満)(良い/良くない)などがそれにあたります。
ここまでの要素で大雑把にどの部分が良かったあるいは良くなかったを把握しました。ここからはより具体的に分解します。
要素3:視点要素
具体的に対象カテゴリーのどのような部分が良かったか・良くなかったかを示す要素です。(コメント内容によっては省略される場合があります。)
要素4:状態要素
基本的に視点要素がどのような状態であったので良かったか・良くなかったかを示す要素です。(コメント内容によっては省略される場合があります。)
標準出力(サマリシート)
基本要素サマリ
対象カテゴリーのアフターコード発生頻度(小計)を実数と構成比でプロットしています。
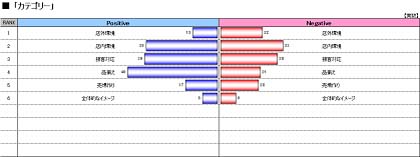
カテゴリー別サマリ
対象カテゴリー別に発生頻度の高いアフターコードを上位10位まで実数と構成比でプロットしています。
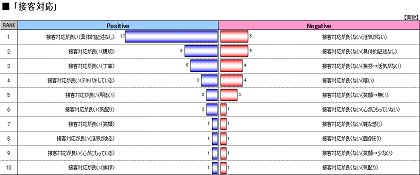
全体発生頻度
全てのアフターコードを発生頻度の高い順に実数と構成比でプロットしています。
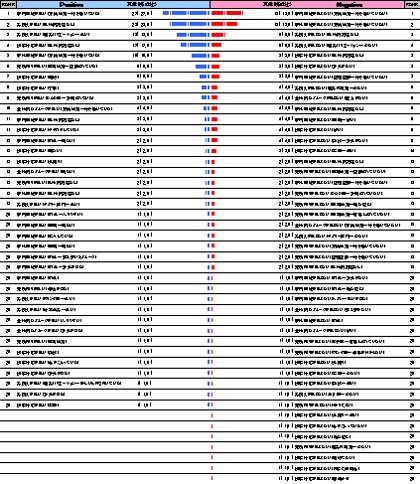
標準出力(クロスシート)
発生した全てのアフターコードを任意のクロス軸で集計した表を構成比でプロットしています。シートは全コードをプロットしたものとカテゴリー別にプロットしたものがあり、カテゴリー別のシートは発生頻度が高い順に並べ替えられています。
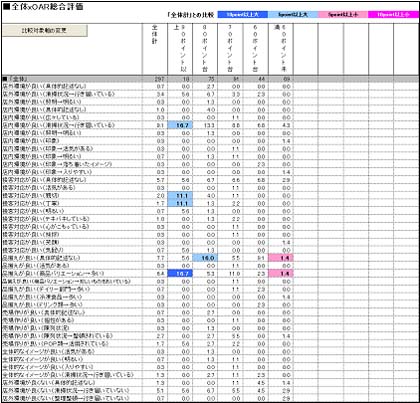
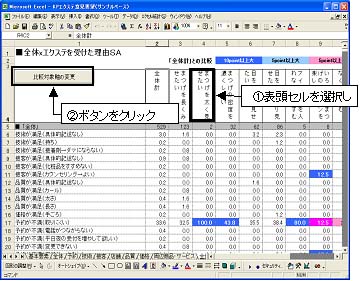
このシートでは「全体計」と比較し差異の大きな軸については以下のように背景色が変更されます。比較基準軸は初期値では「全体計」になっていますが、シートに記録されたマクロで変更することも可能です。

比較基準軸の変更は基準とする表頭セルを選択し「比較対象の変更」ボタンをクリックすることでマクロが実行されます。
納品形態
分析結果はMS-Excel形式のファイルでご提供いたします。ファイルは以下の2つの種類があります。
サンプルベースファイル
サンプルベースファイルは構成比を算出するときにサンプル数を母数としたものです。
コメントベースファイル
コメントベースファイルは構成比を算出するときにコメント数を母数としています。
補助ツール
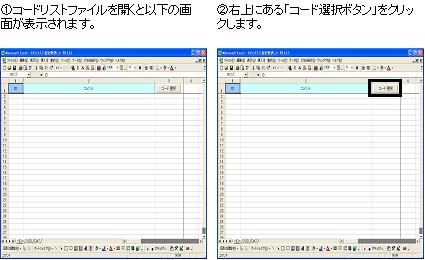
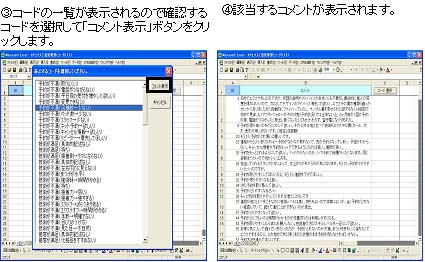
コードリストファイル
分析結果の他に補助ツールとしてコードリストファイルをご提供させていただきます。コードリストファイルはMS-Excel形式のファイルで、アフターコードの元になったコメントを確認するためのマクロが登録されています。
使用方法
メタルラッツマーケットリサーチ株式会社は、商品・サービス・店舗・広告などのマーケティングリサーチを行う市場調査専門会社です。